We took our 36-question IQ test and handed it to five of the most-used AI models. Same questions, same order, same format, every one of them on its free plan. Claude Sonnet 5 scored an estimated IQ of 145. The rest landed between 121 and 129. Below is what happened when the machines sat the test, where they slipped, and the one result we still cannot fully explain.
Quick word on the number first. This is a score on our test, mapped onto the standard IQ scale (mean 100, standard deviation 15). It is an estimate, not a clinical IQ, and we call it estimated throughout for a reason. What it does give you is a clean, like-for-like comparison, because every model answered the exact same paper.
Why we ran this
We wanted a benchmark. Not just for our own future tests, but to show people what these free versions can actually do. AI still feels new to a lot of users, and plenty of them are poking at it right now to see where the edges are. Some are just messing about. Others are working out whether they can bolt it into their job or their daily workflow. If you are one of the second group, a number like this matters. You would not want to trust a model that scored badly on spatial reasoning to read a chart or pull figures out of a screenshot for you.
How we ran the test
We controlled everything we could. Free version of each model, nothing paid. A brand new chat every single time, no memory of anything before it, no system prompt, cache cleared. As far as each model knew, it was seeing the test cold, for the first time.
The written questions, numerical, logical and applied reasoning, were pasted straight in. The spatial questions are visual pattern puzzles, so each one was attached as an image. That detail matters later. On a visual question a model has to do two separate jobs. First it reads the puzzle out of the image. Then it actually solves it. Two stages, two places to fail. You can take the same test yourself and see where you land against them.
The scores
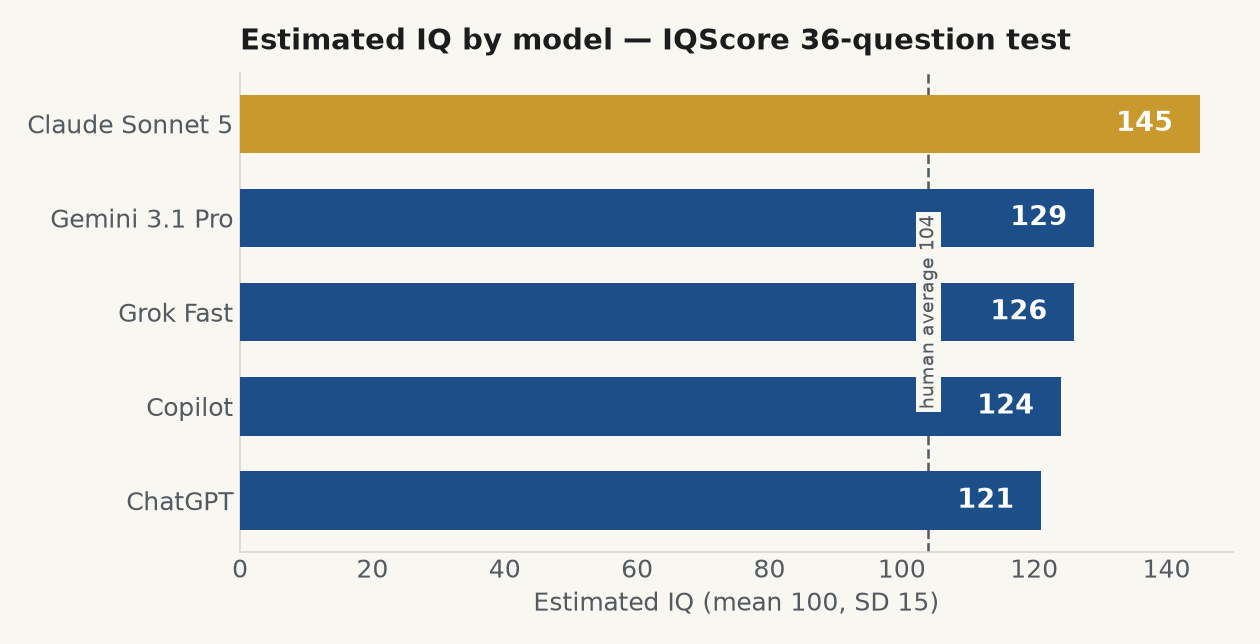
Every model cleared 120. The average person scores 104 on our test, so the gap between the machines and a typical human is real, and it is wide. Here is the full breakdown.
| Model | Estimated IQ | Category | Overall | Spatial | Numerical | Logical | Applied | Easy | Medium | Hard |
|---|---|---|---|---|---|---|---|---|---|---|
| Claude Sonnet 5 | 145 | Very Superior | 36/36 | 9/9 | 9/9 | 9/9 | 9/9 | 12/12 | 12/12 | 12/12 |
| Gemini 3.1 Pro | 129 | Superior | 33/36 | 6/9 | 9/9 | 9/9 | 9/9 | 12/12 | 11/12 | 10/12 |
| Grok Fast | 126 | Superior | 32/36 | 5/9 | 9/9 | 9/9 | 9/9 | 12/12 | 11/12 | 9/12 |
| Copilot (Think Deeper) | 124 | Superior | 30/36 | 4/9 | 9/9 | 8/9 | 9/9 | 11/12 | 9/12 | 10/12 |
| ChatGPT | 121 | Superior | 30/36 | 6/9 | 9/9 | 7/9 | 8/9 | 12/12 | 10/12 | 8/12 |
Sonnet was the only model to hand in a perfect paper, 36 out of 36. Every other model dropped points somewhere, and nearly all of it happened in the same place.
Every model aced the maths
Numerical reasoning was a clean sweep. Nine from nine, all five models, no exceptions. If you have ever watched a teenager feed their maths homework into a chatbot and paste the answers back without reading them, this is the part that explains why it works.
We are not going to pretend that settles the bigger question. You probably still want to grow up able to do basic sums in your head, if only because you cannot outsource everything to a machine. Well. Maybe in a few years you actually can. For now the honest read is a narrow one: on straightforward calculation, these models do not miss.
Discover Your IQ Score
Free 36-question assessment. Instant results. No sign-up required.
Take the Free IQ Test →Spatial reasoning is where they fell apart
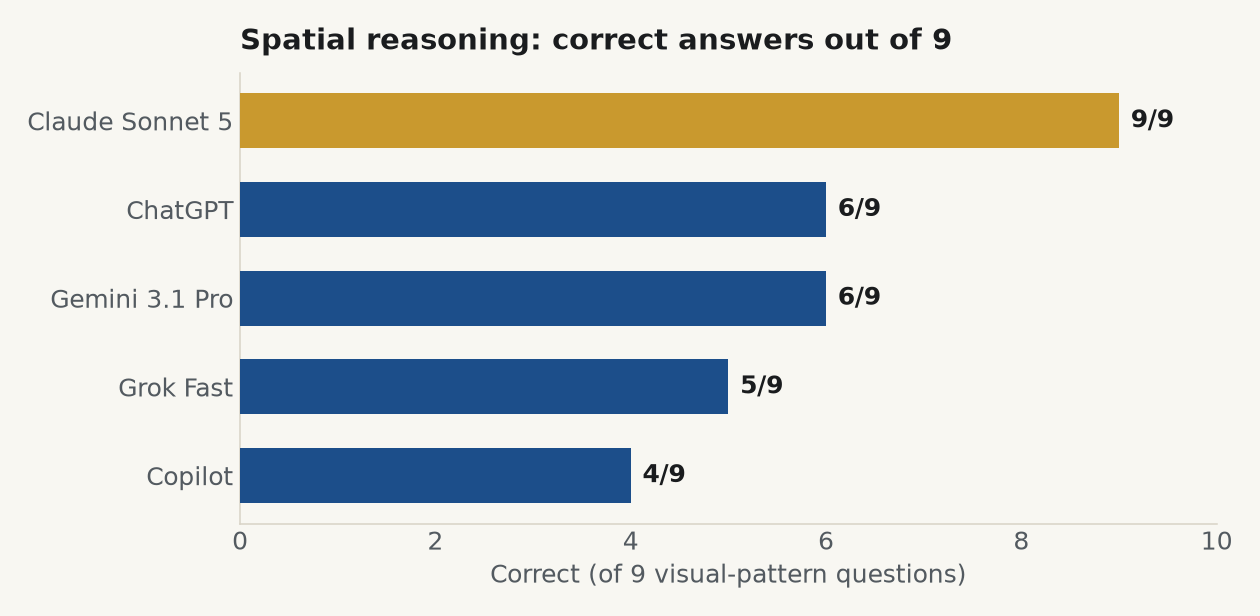
Here is the surprise. On the visual pattern puzzles, the field cracked open. Sonnet went nine from nine. Everyone else sat between four and six. Copilot managed just four.
We cannot tell you exactly why the others struggled, and we will not pretend otherwise. Remember the two stages: pull the pattern out of the image, then reason about it. A model could fail at either one. Maybe it never read the puzzle correctly. Maybe it read it fine and then botched the logic. From the answers alone we cannot separate the two, so that question stays open.
What we can say is that it is not an excuse. Sonnet did both jobs, on the same images, at the same time. So it is possible. The gap is not the task being unfair. The gap is the other models simply being weaker at it, and the data says so plainly.
This is the finding with the most real-world bite. If you are choosing a model to read charts, extract figures from a screenshot, or make sense of an image, a low spatial score should give you pause. There are encouraging signs. None of them scored zero, so a little fine-tuning might close the distance. But right now, for anything visual, they are not equal. Our piece on pattern recognition and IQ covers why this skill sits so close to the core of general reasoning.
The question a chatbot should not miss
Applied reasoning was almost another clean sweep. Everyone scored full marks except ChatGPT, which genuinely surprised us, given it is the model most people actually use. The question it dropped was this one:
Rearrange these words into a proper sentence. What is the third word?
quickly the very ran fox
- A) Fox
- B) Very
- C) Ran
- D) The
- E) Quickly
The correct answer is C, "ran". Put the words in order and it reads "the fox ran very quickly", so the third word is ran. ChatGPT went with B, "very". This is not a hard question. It is the sort of thing you would expect any language model to handle in its sleep.
You know that small line under the chat box, the one that says the AI can make mistakes? This is exactly what it means. If a model can trip on something this simple, the part that should worry you is not the mistakes you catch. It is the ones you never notice.
Two models, two different wrong answers
Logical reasoning split the field again. Sonnet, Grok and Gemini scored full marks. ChatGPT and Copilot both missed the same question, and here is the interesting bit. They gave different wrong answers.
Five people sit in a row. Anna is not next to Ben. Ben is immediately to the left of Clara. David is at one end. Emma is not at either end. Anna is not next to David. What position is Emma in?
- A) 1st
- B) 2nd
- C) 3rd
- D) 4th
- E) Cannot be determined
The correct answer is E, cannot be determined. ChatGPT answered C (3rd), Copilot answered B (2nd). Whether they lose track of who they have already placed, or cannot hold the whole row in their head while they work, we do not know. But two models failing the same puzzle in two different ways tells you something real. They are not running the same reasoning underneath. Different machines, different thought processes, different mistakes.
ChatGPT dropped one more, a process-of-elimination question about reptiles and deserts. We cannot say for certain why. One of our test rules was that every question had to be answered, none skipped. Our best guess is that when it did not know, it guessed, and the guess was wrong. That is a guess about a guess, so we are flagging it rather than concluding it.
The whole picture
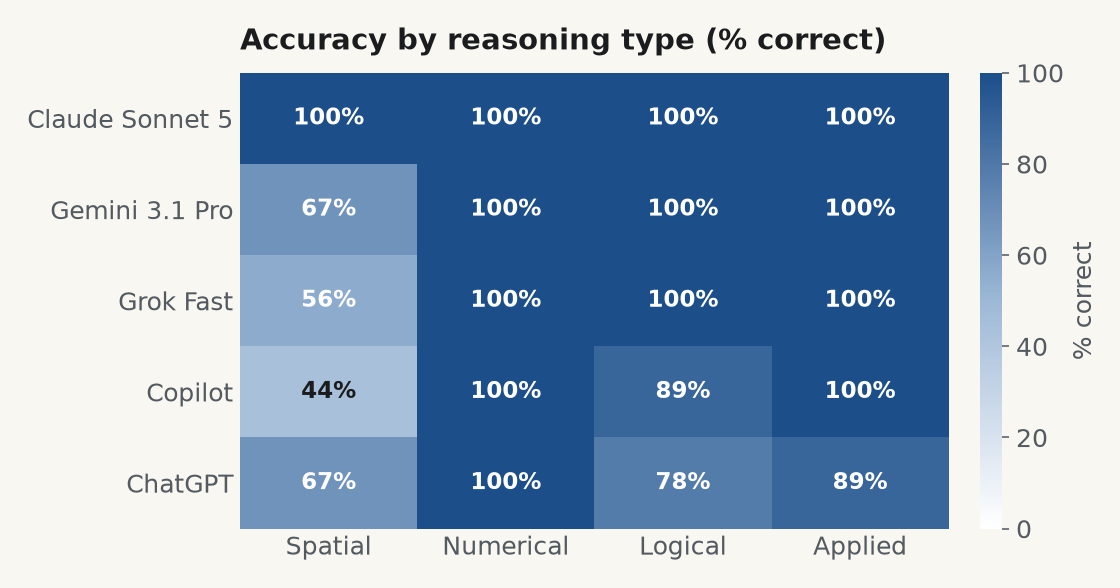
Put it all together and the shape is obvious. Maths is done. Words and logic are nearly there. Visual reasoning is the weak point for every model except one.
So which AI is actually smartest?
On this test, on estimated IQ, there is a clear top scorer. Claude Sonnet 5 beat every other model on every single metric. Not by a whisker either. A perfect paper against a field that all dropped points.
Here is the honest limit of what we ran, though. We used the best free version of each model. We do not know whether the other models' free tiers are quietly held back to nudge you into paying, or whether their paid versions would close the gap or even overtake. We cannot answer that yet. The only way to find out is to run this exact test again on the paid models, and that is the next one we will do.
For now, treat this as the baseline. Five free models, one test, identical conditions. Take it yourself and see how you compare, or read our breakdown of what an AI IQ score actually means.

AJ Dorey
Founder, IQScore
AJ Dorey is an English software developer who researches and writes about intelligence and cognition. He built IQScore because most online IQ tests are broken — they either inflate scores to keep people happy or bury results behind a paywall after 20 minutes of questions.
Curious where you actually rank?
Free IQ test · 36 questions · Instant results · No sign-up
Start Free IQ Test →Already know your score? Convert it to a percentile →